






为未来提供动力: GenAI 供电创新
大型语言模型的功耗要求有多惊人?如何降低功耗?了解模块化电源的作用
随着 AI 训练模型生成的数据量激增,处理能力已经无法满足需求。为了在不超出能源预算的情况下实现最高的计算性能,数据中心需要一种新的供电方法。了解 Vicor 的垂直供电为何是当今机器学习领域最有效的方法。
Vicor 公司战略营销副总裁 Maury Wood 访谈录
生成式人工智能(genAI)越来越受欢迎,但其对计算周期的需求非常大,需要大量电力。应对大规模生成式人工智能的电力需求极具挑战性。《电子设计》(Electronic Design)杂志编辑 Bill Wong 与 Vicor 公司的战略营销副总裁 Maury Wood 进行了对话,深入探讨了这些挑战和解决方案。
OpenAI 于 2022 年 11 月推出了 ChatGPT,生成式人工智能带来的文化影响(以及预期的未来影响)非常大,最终将触及人类活动的各个方面。从技术角度来看,有一点越来越清晰:生成式人工智能模型训练将带来最高的计算性能、存储容量和网络带宽。
生成式人工智能正在推动半导体、基础设施硬件和系统软件以及网络边缘领域的大量新投资。这些投资活动预计将扩展到车辆、家庭和工作场所的嵌入式 AI 设备中。
目前,生成式人工智能训练处理器使用大量晶体管(多达 1000 亿甚至更多),采用 4-nm CMOS 芯粒等先进技术,这些晶体管在运行时会漏电。尽管这些晶体管的供电电压低至 0.7VDD,但持续电流需求可能达到 1000A 或更高,这意味着持续功率(也称为热设计功率)达到 700W。峰值电流需求可能高达 2000A,相当于短时间内的峰值功率达到 1400W 甚至更高。
相比之下,生成式人工智能推理所需的功率要少得多。一个很好的经验法则是,推理能耗大约是训练同一大型语言模型(LLM)的能耗的平方根(图 1)。

图 1:生成式人工智能训练处理器峰值电流需求的演变。
这个问题的难点在于电流需求的高度瞬变,具体取决于训练处理器的算法负载。换句话说,随着神经网络模型任务负载的增加或减少,电流需求会有剧烈波动,每微秒变化甚至可达 2000A。
此外,为了避免晶体管在这些频繁的瞬变过程中受损,任何电压过冲或欠冲必须限制在 10% 以内(即 0.7VDD 时为 0.07V)。这对传统的供电架构来说极具挑战性。
直到最近,数据中心一直使用 12V 直流电源。过去十年中,Vicor 一直倡导在数据中心机架中使用 48V 直流电,因为根据欧姆定律,更高的电压意味着非零电阻导体中的功率损耗更低。Open Compute Project 制定的 Open Rack 规范大大推动了 48V 直流电在高性能计算应用中的采用。
在早期的生成式人工智能供电架构中,标称的 48V 直流电源在加速模块中被转换为中间母线电压。这种中间直流信号通常馈入多相跨电感稳压器(TLVR),但这种方法在可扩展性和电流密度方面存在硬性限制。
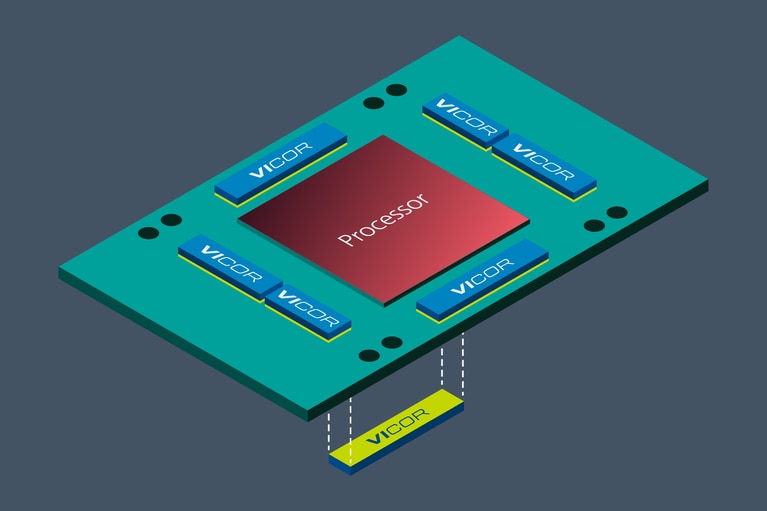
在用于生成式人工智能训练处理器的加速模块(AM)中,印刷电路板(PCB)上的空间非常有限,这意味着这些处理器的供电子系统的功率密度(W/mm²)和电流密度(A/mm²)必须非常高。传统的电源根本无法达到要求,既不能提供所需的电流,也无法适应可用的 PCB 空间。
如前所述,生成式人工智能训练处理器的电源组件必须满足负载阶跃瞬变引起的动态性能要求。同样,传统的供电方法也不适合这些需求,特别是因为生成式人工智能训练处理器需要大约 3mF 的去耦电容尽可能靠近处理器封装(图 2)。
图 2:这个概念性的生成式人工智能加速模块展示了生成式人工智能处理器,支持使用芯粒封装的高带宽内存(HBM)。
此外,生成式人工智能供电架构中的组件必须具有很强的热适应性。无论生成式人工智能系统是液冷还是风冷,电力组件都必须具有高热导率,并且其封装应能够在其生命周期内承受极高的热循环。
更新的生成式人工智能加速模块(AM)使用分比式电源架构,负载点转换器利用电流倍增技术,例如 Vicor 的创新技术。
优化负载点电源组件的物理位置,是降低生成式人工智能的功耗,同时提高供电质量的一种重要方法。将最终阶段的这些电源组件从横向放置改为垂直放置在生成式人工智能处理器的正下方,可以降低 PCB 本身的功耗。由于电流密度约为 3A/mm²,负载点电流倍增器可以共享生成式人工智能训练处理器下方的有限空间。
这种 PCB 热功率减少是因为与纯横向放置电源组件相比,垂直供电(VPD)网络的总阻抗减少了多达 20 倍。
目前,最大的生成式人工智能训练超级计算机包含多达 2 万个加速模块。值得注意的是,NVIDIA 的数据显示,OpenAI 的 GPT-3 模型有 1750 亿个参数,需要大约 300 zettaFLOPS (即每秒 1021 次浮点运算),这意味着在整个模型训练周期内需要进行 30 万亿亿次数学运算。而且,这些模型的规模只会继续增加,目前正在开发的神经网络模型使用的参数已达到万亿级。
Vicor 估计,与传统的 TLVR 横向供电相比,分比式 VPD 可以将每个加速模块的功率降低大约 100W(记住,AI 超级计算机基本上是永久通电的,几乎从不关闭)。
通过合理预测 2027 年全球运营的生成式人工智能数据中心的数量,Vicor 估计总共可以节省数太瓦的电力,相当于每年可节约数十亿美元的电费,减少数百万吨的二氧化碳排放,具体取决于可再生能源的使用比例(图 3)。
图 3:加速模块中垂直放置的电力组件有助于最大限度地减少 PDN 损耗。
多相脉宽调制(PWM)降压调节可以被理解为电流平均化,就像通过动态地混合热水(全峰值电流)和冷水(无电流)来形成温水一样。而 Vicor 的分比式电源架构则完全不同,可以理解为用高效的电压分配来实现电流倍增。
封装在 ChiP™ 产品中的模块化电流倍增转换器与 PCB 板布局兼容,无需大量工程修改即可实现各种电流水平。
这种业界领先的供电架构结合了最先进的正弦振幅转换器(SAC™)电路拓扑。该拓扑使用零电压开关和零电流开关方法来最小化开关噪声和杂散辐射,并最大限度地提高 DC-DC 转换效率。MOSFET 高频开关减少了高度集成模块的物理尺寸。这些设计元素与先进的组件和封装相结合,以应对下一代 AI/HPC 的供电挑战。
台积电(TSMC)等领先的半导体制造商已经公布了未来两到三个工艺节点(2nm、1.6nm)的技术路线图,这些节点采用全新的 CMOS 创新技术,如全栅纳米片或纳米线晶体管。这些器件在物理设计方面的改进以及芯粒封装技术的加速应用,将继续推动生成式人工智能处理器电流水平不断提升。
在算法开发方面,可以肯定的是,主要的大型语言模型(LLM)开发商如 OpenAI、微软、谷歌、Meta 和亚马逊等将继续推进多万亿参数的神经网络模型,这将需要更高的计算、存储和网络通信带宽。
毫无疑问,在可预见的未来,生成式人工智能将继续成为现代计算世界中功耗最高、散热最具挑战的应用。Vicor 将继续创新,抓住这一令人兴奋的新商机,满足不断增长的供电需求。
是的,主要原因在于,我们可以合理地预期企业和个人将在中长期内需要大量的推理带宽。许多甚至大多数生成式人工智能应用程序将使用预训练模型,并通过提示工程进行定制。与推理周期相比,训练周期相对较少(频率低很多个数量级)。
云服务提供商(CSP)将寻找成本最低的推理解决方案。这些解决方案需要支持整数和向量指令(浮点乘加运算)。
CSP 希望尽可能多地同时运行推理任务,推动其处理器架构选择高核数、高带宽的计算引擎,追求每瓦特数万亿次运算(TOPS)的性能指标。高带宽推理处理器应运而生,其中一些处理器的热设计功耗(TDP)高达 500W。我们预计这一趋势将持续并加速发展。
过去几年发布的所有生成式人工智能训练处理器都采用了芯粒封装技术。利用异构逻辑和存储芯粒,处理器开发人员得以突破 Dennard 缩放和摩尔定律的边际效益递减。这两个定律在过去 70 年间共同推动了半导体制造技术的进步,将特征尺寸从 20mm 减小到了 2nm。
生成式人工智能芯粒解决方案通常在一个基板上结合高带宽存储(HMB)设备与图形处理单元(GPU),采用又宽又快的母线连接。台积电最近公布了 2.5D、3D 的 CoWoS 封装技术(a chip-on-wafer-on-substrate)路线图,其目标基板尺寸是 120×120mm,预计电流消耗将达数千安培。Cerebras 的 CS-3 和特斯拉的 Dojo D1 等最新的晶圆级生成式人工智能训练处理器分别消耗约 23kW 和 15kW。
在可预见的未来,生成式人工智能处理器的功率水平似乎将继续快速增长。
本文最初由 Electronic Design 发表。


